28 minutes
Home and Personal Infrastructure Overhaul: Part 2 - Moving to Ansible Roles
In my last post I covered how my home and personal infrastructure management was due an overhaul. When I had first put together all of the configuration management for my home infrastructure, I hadn’t used Ansible in about 3 or 4 years, and was almost starting from zero (especially with the amount of changes that happened to Ansible in that time!).
I had a collection (pun not intended) of single-use playbooks that performed tasks like: -
- Updating DHCP (ISC DHCP) server configuration
- Updating DNS (BIND9) server configuration
- Updating Prometheus configuration (including Alertmanager and associated alert rules)
- Installing Prometheus exporters on new machines
- Installing the
salt-minion(for Saltstack configuration management) package on new machines
To set up a new machine, I had to update a file that contained the machine’s intended IP address, MAC address (for static DHCP allocations) and then run each playbook against it.
This isn’t particularly scalable, and it made moving to a continuous integration system really difficult.
What is a role?
An Ansible Role is a set of tasks that are related to each other, e.g. they configure/install a certain application. More often than not you would create a role to install and configure a single service, e.g. bind for DNS or isc-dhcp-server.
Roles can also be shared (either in your organisation, or publicly). Rather than duplicating code, you can use your own (or other peoples) roles again when the need arises. The Ansible Role Documentation gives a more in-depth overview of what a role is and how to use it.
A Role has a certain directory structure, like so: -
-- roles
|-- base
| |-- defaults
| |-- files
| |-- handlers
| |-- meta
| |-- tasks
| |-- templates
| |-- tests
| |-- vars
|-- dns
| |-- defaults
| |-- files
| |-- handlers
| |-- meta
| |-- tasks
| |-- templates
| |-- tests
| |-- vars
You can create the directory structure yourself, or you can use ansible-galaxy init $ROLENAME. The latter will instantiate a directory with the correct structure, as well as some basic README files, tests and base YAML files to add your tasks/handlers/tests to. Ansible Galaxy is the central repository of Ansible Roles that are shared publicly, but you can use the CLI tool to create local roles without a requirement to share them.
Typically in an Ansible playbook if you want to use a template, a file, handler or anything else you need to give the full path (or at least the relative path) to find them. However within a role, Ansible will look for files in one of the role directories first. For example, if you had a task like the following: -
- name: Copy file to server
copy:
src: myfile.txt
dest: /tmp/myfile.txt
owner: myuser
group: mygroup
mode: 0644
If you place the file myfile.txt in the files directory of your role, Ansible will look there first, meaning you do not need to specify the full/relative path. This allows you to keep all related files, templates and tasks in the same role, making it much easier to share with others. It also helps when you looking at the role again a few months down the line.
How can we use a role?
To use a role, create a directory called roles, add the role in there, and then create a playbook in the top-level directory that references it. The below is a short example of using a role: -
- hosts: all
become: true
roles:
- role: base
tags:
- base
In this, we have included a role called base, as well as adding a tag to it. Tags can be used to run only certain roles/tasks. If you run ansible-playbook --tags base playbook.yml, the only tasks/roles that will run are those tagged with base. This is especially helpful when creating your roles and testing them.
You can also use public roles (from Ansible Galaxy) like so: -
- hosts: all
become: true
roles:
- geerlingguy.docker
If you then add the following to a requirements.yaml file at the base of your repository: -
roles:
- name: geerlingguy.docker
By default this will look for the role in Ansible Galaxy before trying to run against your hosts. You can also refer to roles directly from Git repositories using: -
roles:
- name: nginx_role
src: https://github.com/bennojoy/nginx
version: main
This is how you can share roles in your organisation without necessarily making them available for public consumption.
To specify multiple roles for different hosts in a single playbook, you can do something like the following: -
- hosts: archspire.noisepalace.home
become: true
roles:
- role: blackbox_checks
tags:
- blackbox
- prometheus
- hosts: vmh
become: true
roles:
- role: cockpit
tags:
- cockpit
- hosts: ns-04.noisepalace.home,ns-03.noisepalace.home
become: true
roles:
- role: dns
tags:
- dns
- bind9
- role: dhcp
tags:
- dhcp
What we can see here is that I am running different roles against different hosts, all from the same place. This means that when you run the single playbook, all machines will get the changes they need for every role applicable to them.
Working example: DNS
The best way to show what has changed is to go through a previous example of how I used to update DNS and compare it with what I use now. DNS is a good example because it uses some tasks, installs packages and uses files and templates.
Old Playbook
The previous playbook looked like the below: -
---
- hosts: 192.168.10.1,192.168.10.2
become: yes
tasks:
- name: Install bind9
package:
state: present
name: bind9
update_cache: yes
- hosts: 192.168.10.1
become: yes
tasks:
- name: Pick up vars file
include_vars:
file: ../dhcp/ip-hosts.yaml
name: home_hosts
tags:
- configuration
- name: Pick up net vars file
include_vars:
file: ../netvars.yaml
tags:
- configuration
- name: Generate reverse lookup file
template:
src: named/db.168.192.in-addr.arpa.j2
dest: /etc/bind/db.168.192.in-addr.arpa
tags:
- configuration
- name: Generate forward lookup file
template:
src: named/db.noisepalace.home.j2
dest: /etc/bind/db.noisepalace.home
tags:
- configuration
- name: Named Local
copy:
src: named/named.conf.local.primary
dest: /etc/bind/named.conf.local
tags:
- configuration
- name: Named Options
template:
src: named/named.conf.options.primary
dest: /etc/bind/named.conf.options
tags:
- configuration
- hosts: 192.168.10.2
become: yes
tasks:
- name: Pick up net vars file
include_vars:
file: ../netvars.yaml
tags:
- configuration
- name: Named Local
copy:
src: named/named.conf.local.secondary
dest: /etc/bind/named.conf.local
tags:
- configuration
- name: Named Options
template:
src: named/named.conf.options.secondary
dest: /etc/bind/named.conf.options
tags:
- configuration
- hosts: 192.168.10.1,192.168.10.2
become: yes
tasks:
- name: Stats directory
file:
path: /var/bind
owner: bind
group: bind
mode: '0755'
state: directory
tags:
- configuration
- name: Reload bind9
systemd:
name: bind9
state: reloaded
enabled: yes
tags:
- configuration
There are a few issues with this playbook that I wanted to address: -
- Statically defined hosts
- This means that if I wanted to re-use this with other hosts, I have to update this playbook (and all the host declarations inside of it)
- The same/similar tasks repeated
- BIND9 will be reloaded at the end of this playbook, even if nothing changed
- We refer to two different sets of variables files, including one that is in a different “roles” directory
- As this didn’t use true Ansible Roles before, I refer to a role here as a different directory of Playbooks
- One of the sets of variables is imported with a prefix of
home_hostson every variable
Some of this is down to my understanding when creating the Playbooks, but some of it was down to just wanting to get it to work and then change later (which I expected to happen much sooner than 2 years later!). For those who know how often a temporary fix becomes semi-permanent, this shouldn’t come as too much of a surprise 😄.
An example of the variables are below: -
ip-hosts.yaml
home_hosts:
router:
mac: c4:ad:34:55:cb:03
ip_addr: 192.168.0.1
VanHalen:
mac: 02:95:09:c0:d1:9a
ip_addr: 192.168.0.3
archspire:
mac: f4:4d:30:64:4d:bf
ip_addr: 192.168.0.5
pinkfloyd:
mac: a8:20:66:34:f0:2b
ip_addr: 192.168.0.6
[...]
behemoth:
cname: behemoth-10g
pihole:
cname: netutil-01
grafana:
cname: pinkfloyd
prometheus:
cname: pinkfloyd
netvars.yaml
netvars:
ip_ranges:
- 192.168.0.0/24
- 192.168.2.0/24
- 192.168.3.0/24
- 192.168.4.0/24
- 192.168.5.0/24
- 192.168.10.0/24
- 192.168.20.0/24
- 192.168.99.0/24
- 192.168.100.0/24
- 192.168.255.0/24
Old templates
The previous templates used looked like the below: -
db.noisepalace.home.j2
;
; BIND data file for local loopback interface
;
$TTL 604800
@ IN SOA noisepalace.home. root.noisepalace.home. (
2 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS ns4.noisepalace.home.
@ IN A 192.168.10.1
ns3 IN A 192.168.10.2
ns4 IN A 192.168.10.1
{% for name in home_hosts.home_hosts %}
{% if "cname" in home_hosts.home_hosts[name] %}
{{ name|lower }} IN CNAME {{ home_hosts.home_hosts[name]['cname'] }}
{% else %}
{{ name|lower }} IN A {{ home_hosts.home_hosts[name]['ip_addr'] }}
{% endif %}
{% endfor %}
While this is mostly okay, we could clean up the conditional check on CNAMEs and A records. Also having every variable prefixed with home_hosts is redundant.
db.168.192.in-addr.arpa.j2
;
; BIND reverse data file for the Noise Palace
;
$TTL 604800
@ IN SOA noisepalace.home. root.noisepalace.home. (
1 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS noisepalace.home.
{% for name in home_hosts.home_hosts %}
{% if home_hosts.home_hosts[name]['ip_addr'] is defined %}
{% set octet = home_hosts.home_hosts[name]['ip_addr'].split('.') %}
{{ octet[3] }}.{{ octet[2] }} IN PTR {{ name | lower }}.noisepalace.home.
{% endif %}
{% endfor %}
Other than the home_hosts prefix on this, this is okay. It does hard-code the domain name, but I only use one domain in my home infrastructure anyway, so I’m okay with this trade-off for now.
Other templates
The other templates are standard BIND9 configuration defining my zones, what I forward to for recursive DNS and other standard features. The only interesting part I have is adding my subnets in as “goodclients” (i.e. those that are allowed to query DNS from BIND9): -
acl goodclients {
{% for network in netvars['ip_ranges'] %}{{ network }};
{% endfor -%}
localhost;
};
New Role: Outline
As noted, the previous approach had a few limitations that I wanted to address. The below is a quick summary of what I want to fix in the tasks: -
- Statically defined hosts
- Repetition of tasks
- Only reload/restart
bind9if a change has been made - Consolidate the variables into a single file, available globally across all roles and hosts
- Remove redundant prefixing/namespacing of variables
For the templates, I wanted them to be simpler with less conditional logic.
Finally, I wanted to remove the primary/secondary roles from the servers, and just have each server answer with what it has.
I have found a few issues with records not replicating correctly between my two instances of bind9. Given both are managed with Ansible anyway, I don’t need to have the primary inform the secondary of what records exist.
New Role: Initialisation
To initialise the role, I ran ansible-galaxy init dns in the roles directory of my Ansible repository. I also added it to my overall Playbook like so: -
- hosts: ns-04.noisepalace.home,ns-03.noisepalace.home
become: true
roles:
- role: dns
tags:
- dns
- bind9
In the above, I have applied the role to my ns-04 and ns-03 hosts (two virtual machines on my network).
This is because the role is solving the Statically defined hosts issue. If I wanted to add additional servers, I can add them to the hosts list in the overall Playbook, rather than updating the role itself.
As an aside, why do I have ns-04 and ns-03 rather than ns-01 and ns-02? The simple reason is that when I moved from running everything on two Raspberry Pis and onto my two home servers, I didn’t want to end up breaking DNS in my house.
I had records for ns-01 and ns-02 pointing to the Raspberry Pis, so I could add the new servers, move all other machines/DHCP pools/anything else reliant on DNS to use the new machines, and then decommission the Raspberry Pis. If I had simply tried to replace them and it turned out I’d made a configuration error, I would have broken DNS (including access to the internet to help me fix it!).
New Role: Tasks
The tasks Playbook in roles/dns/tasks/main.yml looks like the following: -
---
# tasks file for dns
- name: Generate reverse lookup file
template:
src: db.168.192.in-addr.arpa.j2
dest: /etc/bind/db.168.192.in-addr.arpa
owner: root
group: bind
mode: 0644
notify:
- Reload bind9
tags:
- configuration
- name: Generate forward lookup file
template:
src: db.noisepalace.home.j2
dest: /etc/bind/db.noisepalace.home
owner: root
group: bind
mode: 0644
notify:
- Reload bind9
tags:
- configuration
- name: Named Local
template:
src: named.conf.local.j2
dest: /etc/bind/named.conf.local
owner: root
group: bind
mode: 0644
notify:
- Reload bind9
tags:
- configuration
- name: Named Options
template:
src: named.conf.options.j2
dest: /etc/bind/named.conf.options
owner: root
group: bind
mode: 0644
notify:
- Reload bind9
tags:
- configuration
- name: Stats directory
file:
path: /var/bind
owner: bind
group: bind
mode: '0755'
state: directory
tags:
- configuration
We have fewer tasks compared to the original Playbook This is partly due to reducing repetition and partly due to moving away from primary/secondary replication.
We also use something called notify. The purpose of notify is to trigger a Handler. When using templates and files, if a change has occurred, the handler is triggered. If no changes were required to the files on the servers, the handler is not triggered.
One interesting advantage of using handlers is that if multiple tasks refer to the same Handler, Ansible will wait until the last time it is called before triggering. This means that we don’t restart the service multiple times during the Playbook.
The handler is defined in roles/dns/handlers/main.yml as such: -
---
# handlers file for dns
- name: Reload bind9
systemd:
name: bind9
state: reloaded
enabled: yes
tags:
- configuration
This achieves the aims of reducing repetition of tasks, and only restarting/reloading bind9 when needed.
New Role: Templates
In terms of templates, I was able to remove a few (due to getting rid of Primary/Secondary roles). For the ones left, I made a couple of changes to make them easier to work with, and to provide more comments/help when reading the output files at a later date.
roles/dns/templates/db.noisepalace.home.j2
;
; BIND data file for local loopback interface
;
$TTL 604800
@ IN SOA noisepalace.home. root.noisepalace.home. (
2 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS ns4.noisepalace.home.
@ IN A 192.168.10.1
ns3 IN A 192.168.10.2
ns4 IN A 192.168.10.1
{% for network in networks %}
; Subnet: {{ network['subnet'] }}
; Purpose: {{ network['purpose'] }}
{% for host in network['hosts'] %}
{{ host['name']|lower }} IN A {{ host['ip_addr'] }} ; {{ host['description'] }}
{% endfor %}
{% endfor %}
{% for domain in cnames %}
{% for record in domain['records'] %}
{{ record['name']|lower }} IN CNAME {{ record['cname'] }}
{% endfor %}
{% endfor %}
The redundant home_hosts prefix when looping through variables has been removed. The conditional check on whether this is a CNAME or an A record has also been removed (as CNAMEs are now in their own section of the variables). We also add some comments in to make the resulting file easier to navigate.
I will go through what has changed in the variables file soon so that you can see where the information is sourced from.
roles/dns/templates/db.168.192.in-addr.arpa.j2
;
; BIND reverse data file for the Noise Palace
;
$TTL 604800
@ IN SOA noisepalace.home. root.noisepalace.home. (
1 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS noisepalace.home.
{% for network in networks %}
; Subnet: {{ network['subnet'] }}
; Purpose: {{ network['purpose'] }}
{% for host in network['hosts'] %}
{% set octet = host['ip_addr'].split('.') %}
{{ octet[3] }}.{{ octet[2] }} IN PTR {{ host['name']|lower }}.noisepalace.home.
{% endfor %}
{% endfor %}
This doesn’t differ much from the original template, except for some additional comments for each subnet. Still, we have removed the redundant home_hosts prefix on all the variables, so that is a win!
New Role: Variables
This section isn’t specific to this role. However it will help to show the difference between using local/directory-specific variables and using global variables usable by all hosts and roles.
Previously the variables for this role were found in other directories. We had to have specific tasks to include them in the Playbook (and any others that required it). The same would be true for any other application/Playbook I had created, as there was no global definition of variables.
Now in the overall Playbook, we have the following: -
- hosts: all,localhost
become: false
pre_tasks:
- name: Include Global vars
include_vars: vars.yml
tags:
- vars
This includes a global variables file that is available to all hosts and for all roles. Any changes in the global variables file are then available to all roles that require them.
I also changed the format of the variables to look like the below: -
[...]
networks:
- subnet: 192.168.0.0/24
purpose: Management
domain: noisepalace.home
hosts:
- name: router
mac: c4:ad:34:55:cb:03
ip_addr: 192.168.0.1
description: "Core Router - MikroTik 4011 Core"
monitor:
icmp: yes
mikrotik_snmp: true
- name: archspire
mac: f4:4d:30:64:4d:bf
ip_addr: 192.168.0.5
description: "Archspire - Intel NUC VMH"
- name: pinkfloyd
mac: a8:20:66:34:f0:2b
ip_addr: 192.168.0.6
description: "PinkFloyd - Mac Mini VMH"
[...]
cnames:
- domain: noisepalace.home
records:
- name: behemoth
cname: behemoth-10g
- name: pihole
cname: netutil-01
- name: grafana
cname: pinkfloyd
- name: prometheus
cname: pinkfloyd
[...]
Before everything was a dictionary (i.e. keys and values). Now I have moved to using lists for the variables I want to iterate over. I find lists slightly easier to use in Jinja2 templates, and I also find it helps at first glance to see where one host starts and one host ends.
You’ll also notice that each subnet has a purpose (i.e. the kind of hosts that exist in it) and also each host has a description.
We saw in the templates that each DNS record has a description next to it (as the hostname alone may not always show enough information). Also all the records in a subnet will be prefixed by a comment that has the CIDR range (e.g. 192.168.0.0/24, 192.168.10.0/24) as well as the purpose of the subnet.
New Role: Summary
At this point, the role can now be used against multiple hosts (i.e. not hardcoded to two hosts), we’ve reduced repetition, made the variables available to all roles and we only perform a reload/restart on bind9 when required. The templates have been simplified (while also giving more information in the output files) and the primary/secondary DNS roles are gone.
I went through a similar exercise against other Playbooks, combining all variables that would be useful to other hosts into the global variables files, reducing repetition, and using handlers in all places I could.
What other roles do I use?
As well as the aforementioned DNS role, I have a number of other roles defined in my overall Playbook: -
base
This is the base role for anything I might want against all hosts.
Currently, this just installs gnupg2 on any Debian machines. Without it, adding Debian repositories fails because of a lack of GPG-key management software.
sshkeys
This takes my public SSH keys from my workstations/laptops/desktops/terminal apps on phones/tablets and adds them to the authorized_keys files for my primary user on each provisioned machine.
authkeys
This takes the same keys as above, but adds them to my Gitea, Gitlab and GitHub user so that I can clone my repositories using SSH.
Rather than using a native Ansible module for this, it uses a small Go tool I built to interact with the Gitea/Gitlab/GitHub APIs. I created the tool in part help learning Go, and it also makes adding other Git/VCS providers quite straightforward in future.
saltstack
This role adds the Saltstack repositories to any Debian or RHEL-based machine. These are the only official repositories available for distributions I use (i.e. Debian and Ubuntu primarily, with Alma/Rocky for testing sometimes).
It will then install the salt-minion package (from the official repository if available, from the distribution packages if not), update the configuration file to point to my Salt Master server, add a few useful grains and then restart the salt-minion daemon (to force it to register with the Salt Master).
blackbox_checks
For any hosts not managed by Salt (i.e. routers, switches, access points, IoT devices), this role will add them to my Prometheus checks so that I can monitor and alert on them. This uses the Prometheus blackbox_exporter that I have detailed in other posts.
cockpit
This install Cockpit on my hypervisors. This is only used for Virtual Machine consoles when I am not on a machine with virt-manager available, but it is useful to have nonetheless.
dhcp
This installs isc-dhcp-server, configures the pools for each of my subnets (i.e. one per VLAN in my network), any static IP reservations, and then reloads isc-dhcp-server when required.
drone
This installs the drone-exec-runner on two of my machines (one arm64 based, one that is running the Salt Master). I will go into much more detail on this in a later post.
cloudflaredns
For a number of DNS records, I add them to Cloudflare (who I use for DNS). The reason for this is so that I can use one of my purchased domains with Lets Encrypt to get valid certificates for the hosts on my network.
Quite a few applications now either warn when HTTPS isn’t used or uses a self-signed certificate. Some browsers now make you type thisisunsafe to accept a self-signed certificate. Other applications won’t even work without HTTPS.
I have been running HTTP only on any application in my network for years now, but I decided it was time to start using HTTPS properly.
As Cloudflare is my public DNS provider, I will toggle what hosts I want in my variables file using cf_add: true, and then they will be added to the zone for my purchased domain.
ipam
I run an instance of Netbox on my network, but I have been updating it manually. This role updates IP entries automatically, meaning I can see how much space I have left in each subnet, as well as just a general overview of what I have running.
All of the above roles make use of the same global variables files. This allows me to feed the DNS, DHCP, IPAM and Cloudflare roles with the same information.
The final overall Playbook that runs all of these roles looks like the following: -
- hosts: all,localhost
become: false
strategy: mitogen_free
pre_tasks:
- name: Include Global vars
include_vars: vars.yml
tags:
- vars
- hosts: config-01.noisepalace.home
strategy: mitogen_free
roles:
- role: sshkeys
tags:
- sshkeys
- authkeys
- hosts: all
strategy: mitogen_free
become: true
roles:
- role: base
tags:
- base
- role: authkeys
tags:
- authkeys
- role: saltstack
tags:
- saltstack
- hosts: archspire.noisepalace.home
strategy: mitogen_free
become: true
roles:
- role: blackbox_checks
tags:
- blackbox
- prometheus
- hosts: vmh
strategy: mitogen_free
become: true
roles:
- role: cockpit
tags:
- cockpit
- hosts: ns-04.noisepalace.home,ns-03.noisepalace.home
strategy: mitogen_free
become: true
roles:
- role: dns
tags:
- dns
- bind9
- role: dhcp
tags:
- dhcp
- hosts: piutil-01.noisepalace.home,config-01.noisepalace.home
strategy: mitogen_free
become: true
roles:
- role: drone
tags:
- drone
- connection: local
strategy: mitogen_free
hosts: localhost
become: false
roles:
- role: cloudflaredns
tags:
- cloudflaredns
- dns
- role: ipam
tags:
- ipam
Mitogen?
One of the benefits of moving to Roles is making a change to a single variables file, and all the roles that use the added/changed variable (e.g. adding a new host/IP address) will roll out at the same time (so long as you don’t use ansible-playbook --tag $TAG or ansible-playbook --skip-tags $TAG).
The new Playbook and roles now runs against all of the hosts in my home and personal infrastructure. A change to add a new host will still run all the other roles too, even though not all may be relevant to it.
This means that a quick addition/fix takes much longer than it used to. There are a couple of tweaks you can do to speed up Ansible compared to the default behaviour.
General Ansible performance improvements
The first tweak is changing the “strategy”. The strategy defines the way Ansible runs tasks.
By default, Ansible uses the linear strategy. For each task in a playbook, Ansible waits for a response from each server that the task runs against before moving onto the next task.
Changing this to free means that each host will try to reach the end of the Playbook in the quickest time it can without waiting for other hosts.
Changing your default strategy to free can help with getting some hosts to complete as quickly as they can. This can help with overall Playbook execution time, and means that not all hosts are penalised by the slowest one.
The second tweak is to increase the amount of forks the Ansible process will make.
A fork is a separate process of Ansible that will run concurrently with others. If you have multiple cores on your machine(s) available, this will speed up time to process the playbooks by allowing Ansible to execute tasks concurrently. The more threads available, the less the instructions contend with each other for CPU time.
Is it enough?
Even with the above tweaks, the execution time for a Playbook with a few roles can still be significant.
Previously the single Playbooks I used would take around 1-3 minutes to execute. This depended on the amount of tasks, amount of files to manage and any loops. I may have been running multiple Playbooks, but if I only wanted to update DNS, it would only take or a minute or two.
With the move to using a number of roles against multiple hosts, the overall execution time reached around 15-20 minutes. If I had to run every single one of my old Playbooks, this may have taken a similar amount of time. However other than adding a brand new host, it was rare that I needed to run lots of Playbooks at once.
At this point, I was considering separating out the single Playbook with multiple roles into a few separate playbooks with some of the roles. I could then add in conditional checks (or even run separate repositories) so that each role didn’t need to run every time.
However this goes against the idea of moving to this approach, in that a single variable change may affect multiple Roles, so having some Playbooks run and not others could leave drift in configuration. Also, if I did need to run every role (i.e. new host being added), it would still take the full execution time anyway.
After a little research on improving Ansible performance and execution time, I came across Mitogen.
What is Mitogen?
Mitogen is a Python library that is used to write distributed programs, and to provide native Python APIs where shell commands/interaction is usually required. While Ansible does primarily use Python, it also does call out to the shell from Python for quite a few different operations.
Mitogen also provide a way to use the library with Ansible directly. It replaces (where possible) calling out to the shell with pure Python equivalents, re-uses SSH connections and more. Mitogen claims that this will speed up Playbook execution anywhere from 1.5 to 7 times, as well as reducing CPU consumption considerably. They specifically mention that any task/action that uses loops or with_* directives should see noticeable improvements.
To use Mitogen with Ansible, there are a couple of options. If you plan to run Ansible from a standard host (i.e. a bastion host, your machine), then either clone the repository from their GitHub (or download a release tarball from their releases page) and refer to the location of the repository/extracted files in your Ansible configuration.
If you intend to run Ansible from a container/image, then you need to ensure that either the image/container has Mitogen installed/included, or that it is included as part of your Ansible repository.
To include it in your repository, you can either add it as a Git submodule, or extract the contents of the release tarball into a directory in your repository directly.
Once you have done this, create/update ansible.cfg in your repository with the following: -
[defaults]
host_key_checking = False
strategy_plugins = mitogen/ansible_mitogen/plugins/strategy
I have disabled host_key_checking because if Ansible runs in an ephemeral container, it hasn’t SSH’d to any of the hosts previously. Without this, running Ansible will fail from a container, as the process for accepting a host key would require user input.
In addition to this, I add the strategy: mitogen_free to the tasks in the overall Playbook. You can set this as a default option in the ansible.cfg file.
I have found that some roles/collections may have issues with Mitogen (the netbox collection didn’t work on a release candidate of Mitogen, but does work on the latest GA release). Having the option to enable it per task/role inclusion allows me to run it against all roles it is compatible with, and revert to the in-built Ansible strategies if a role/collection has issues.
Did it make a difference?
All of this would be moot if there were no improvements in execution time. So what difference has it made?
I am skipping ahead in the series slightly in showing the results from my Drone CI jobs. They are a good benchmark for the time to execute all the roles, and all of them run all roles defined in the overall Playbook.
Only using forks
I set the amount of forks set to 15 ever since I started moving to roles, so I don’t have any benchmarks/execution times without it!
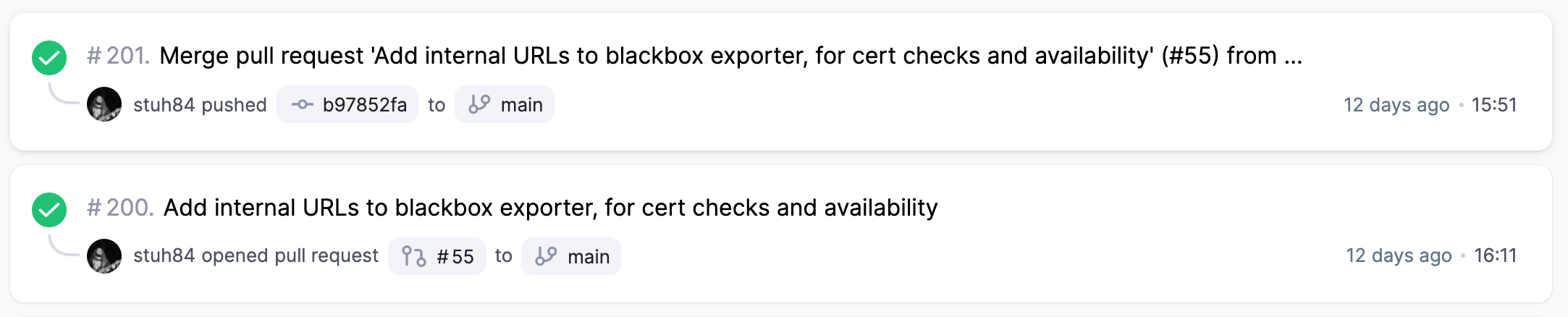
The times at the end (15:51 and 16:11) are how long the jobs (in minutes and seconds) have taken to execute. The Pull Request (using --check and --diff mode only, no actual changes applied) takes just over 16 minutes. When the PR is merged, it takes just under 16 minutes.
This is quite a long time to wait for a single DNS change or adding a host!
Using the standard free strategy
My first attempt to reduce the execution time was to change the strategy to free: -

That is quite an improvement, saving 4 and 5 minutes of execution time.
Allowing hosts to get to the end of a playbook quicker saves on execution time overall. This makes sense, as some hosts may be quicker at some tasks and slower at others. Allowing them to not be penalised by other hosts (or to not slow down other hosts) cumulatively saves time overall.
Using Mitogen
We are already using the free strategy, so what difference do we see when moving to mitogen_free?

Wow, that is a huge difference! I can now do a full Pull Request AND Merge executions in less time than it had taken to run one or the other before.
5 minutes of execution time is still more than the 1-3 minutes it used to take to apply my single Playbooks previously, but bear in mind that this is now applying 11 roles against all hosts. For me, this is an acceptable trade-off for knowing that every host has all roles and the latest changes applied.
Other changes
If you look over my list of roles I now use with Ansible, you may notice something missing.
Didn’t you say you used Ansible to configure Prometheus?
Yes, earlier in this post I mentioned that before this refactor, Ansible would: -
Update Prometheus configuration
Install Prometheus exporters on new machines
Why wasn’t it included in the “What other roles do I use?” section?
As part of this refactor, I thought about why I run both Ansible and Saltstack in my home infrastructure. Both achieve very similar goals.
One of the main differences between the two is that Ansible isn’t agent-based. It doesn’t need a machine/node to be bootstrapped/have additional packages installed to manage it, which is very useful when configuring a brand new host.
However Salt is incredibly quick in my experience. The section on performance tweaks and using Mitogen with Ansible is something you don’t necessarily need to think about too much with Salt, as it has a lot of performance advantages to begin with.
Salt uses a queuing mechanism (based upon ZeroMQ). The Salt Master doesn’t tell each node what to do directly. Instead it adds messages to the queue and then the Agents will execute the actions describe by the messages (more information on this here).
The Salt agents then execute all the commands and operations to configure the server they run on. By contrast, Ansible has to tell each host what command/execution/task are required, and controls the order/strategy to execute them.
Because of this, I decided to use Ansible for what it is (in my opinion) best at, bootstrapping nodes (i.e. installing allowed SSH keys, configuring DHCP/DNS, installing the Salt agent) and managing nodes that can’t run agents.
Ansible knows about every host on my network (in that there are variables that have the IP address/MAC address etc) for anything that needs a static allocation and needs basic monitoring (i.e. those that cannot run agents themselves), so it makes sense to add them into monitoring/DNS/DHCP with Ansible during the bootstrap/playbook run stage.
For hosts that can run Agents (i.e. all my home servers/virtual machines/VPSs etc), everything other than the initial bootstrap is managed by Salt. They get a default set of Prometheus exporters, ICMP monitoring, base packages and more. I can then include other applications for the machine to run, as well as the associated Prometheus exporter(s) that will be monitor the deployed applications (e.g. Wireguard and the wireguard_exporter, Docker and cadvisor).
To show the difference in execution time between the two, here is an example of Salt running against all hosts, applying all relevant states: -

My Salt environment has 47 different states/applications it can deploy. Even with all the tweaks I have done to my Ansible setup, Salt achieves a lot more in a lot less time!
This isn’t to say Ansible is bad, as it isn’t. I love and use Ansible in a lot of different ways, and could easily use only Ansible to manage everything on my infrastructure.
I like the option of having both Ansible and Salt. I can play to their strengths, rather than making compromises to use only one or the other.
Summary
Hopefully this post helps you in either understanding Ansible roles, how to transition from single Playbooks to Ansible Roles (and why you would want to) and also helps with reducing the execution time of your Playbooks too.
The move from single Playbooks to Roles was probably the biggest part of the refactor, but I am now able to rely solely on my continuous integration to test and implement my Playbooks. Being able to trigger a full update of my infrastructure by making updates in the Gitea mobile app (GitNex) is a wonderful thing 😁.
Next post
In the next post, I will cover the changes that have improved my Salt environment. This isn’t as big of an overhaul as Ansible was, as I already had recent professional experience of Salt when I started using it at home.
However there are a few interesting changes I made that require less manual updates to the Salt states and pillars, or any in the case of a host that I am just testing/not running extra applications on.